How data fidelity drives machine learning accuracy in polymer solubility prediction
Advances in data science and machine learning enable predictive modeling of material properties, accelerating materials development. Polymers are especially promising targets, given their widespread industrial use and strong sensitivity to processing conditions. However, reliable prediction remains challenging because polymer behavior depends on experimental parameters – such as temperature, concentration, and molecular weight – that are often inconsistently controlled or reported in existing datasets.
In this article, we present a study that examined how experimental data fidelity influences machine learning performance for polymer solubility prediction. By comparing models trained on low-fidelity visual inspection data with those trained on high-fidelity turbidity measurements collected under controlled conditions using Crystal16, the study highlights the importance of standardized, well-controlled experimental workflows for building reliable polymer informatics models.

Experiment data generation
Visual inspection:
All samples prepared with 25 mg of polymers in 5 mL of solvents and accessed through visual inspection at three different temperatures of 25 °C, elevated temperature (65–70 °C), and cold temperature (5–10 °C). At each temperature, samples were mixed at 700 rpm and allowed to equilibrate overnight before evaluation.
The solubility was reported as soluble for fully clear solutions, partially soluble solutions were mostly clear but contained small visible particles, whereas insoluble solutions were cloudy or showed polymer settling at the bottom as shown in Figure 1A. The distribution of the visual inspection data across different temperatures is shown in Figure 1C.
Turbidity Measurement:
Solubility measurements were collected using the Crystal16 where % transmission was monitored during controlled heating and cooling cycles. Experiments were conducted between 10 °C and 60 °C at a constant ramp rate of 0.5 °C/min, mixing speed of 900 rpm with defined isothermal holds, allowing up to 16 polymer–solvent systems to be evaluated in parallel.
Processed transmission data during the isothermal hold were extracted and filtered to remove highly variable measurements, and solubility behavior was categorized as soluble when the %transmission was above %85, partially soluble when the %10<%transmission<%85, or insoluble for %transmission<%10.
Data across multiple concentrations were retained to maintain balance between number of datapoints, enabling a consistent comparison between high-fidelity turbidity measurements and low-fidelity visual inspection results. The comparison of the solubility classes for both datasets is shown in Figure 1B.
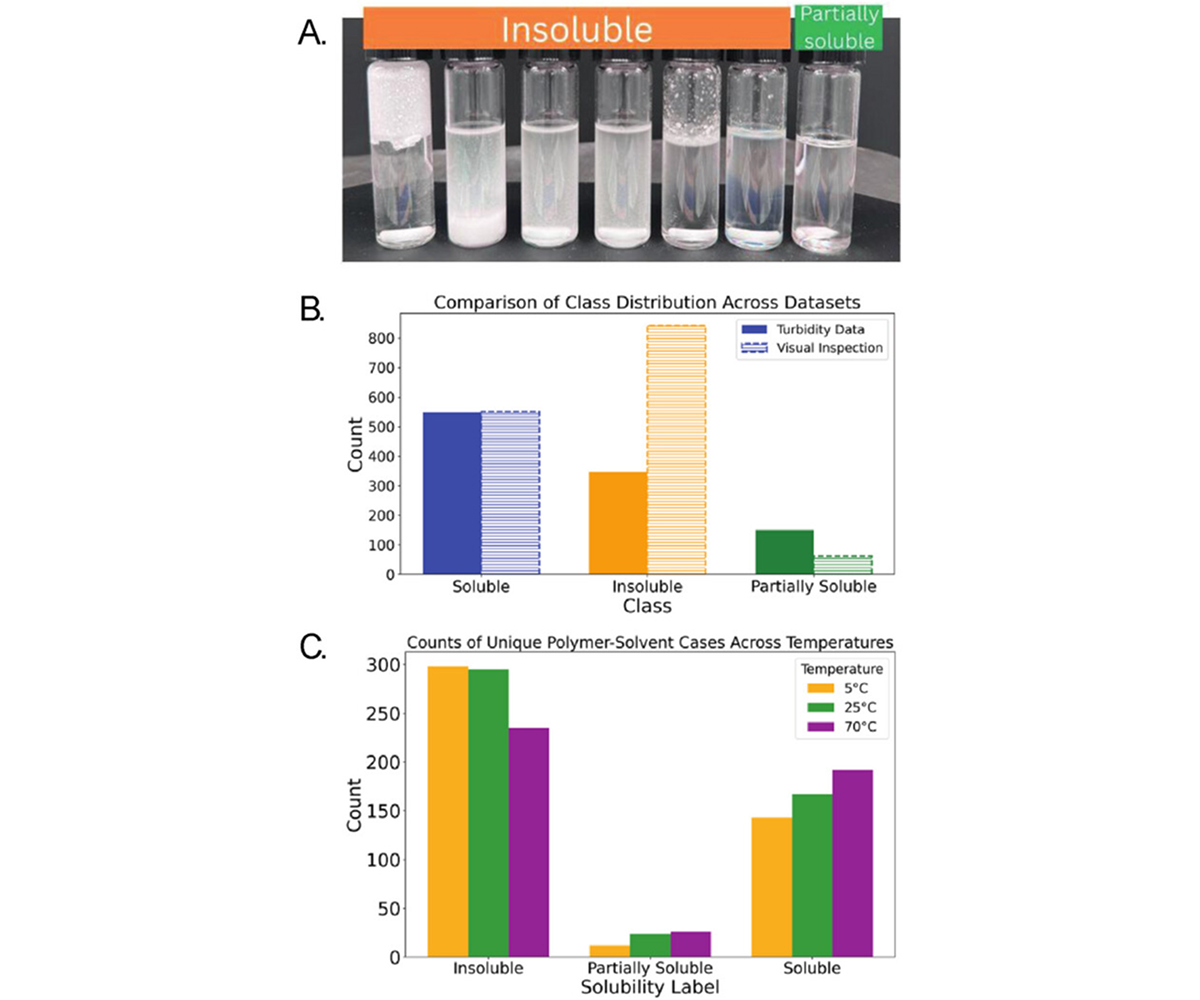
Figure 1: Visual inspection classification of polymer–solvent samples. Fully clear solutions were labeled as soluble, samples with visible particulates as partially soluble, and cloudy or precipitated samples as insoluble. (B) summarize the distribution of solubility classes across the two datasets and (C) summarize the distribution of solubility classes in visual inspection dataset across different temperatures.
Results: model performance comparison across data fidelity
The paper compares a classification model built using one-hot encoding for polymers and Morgen fingerprints for solvents with XGboost classifier. Figure 2 shows the results of the classifiers trained on low-fidelity visual inspection data (Figure 2A) in distinguishing solubility classes. The goal is the predicted values for each solubility class to match the experimental results which are reflected on the diagonal values. The ML classifier model using high-fidelity Crystal16 data (Figure 2B) shows clearer separation between classes and better capture of partially soluble behavior, underscoring the value of quantitative measurements over subjective visual labels.
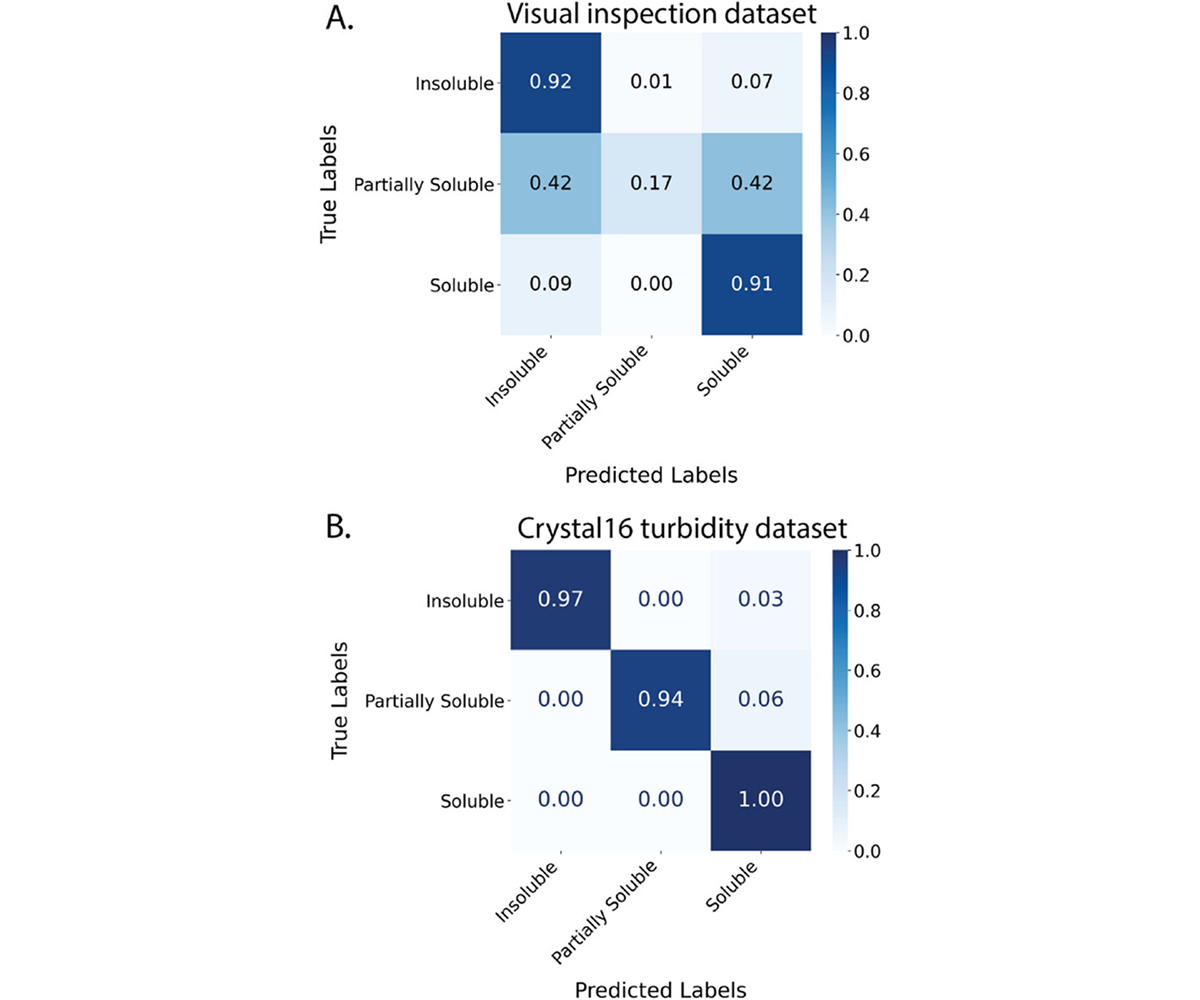
Figure 2: Normalized confusion matrices for the test sets comparing (A) the visual inspection dataset containing 1,455 data points and (B) the Crystal16 turbidity dataset containing 1,045 data points for the same set of polymers.
Impact of including temperature on model accuracy
This study demonstrates the importance of including temperature as an input feature in machine learning models. Even limited temperature information leads to a consistent improvement in model accuracy, indicating that lower-fidelity datasets become more informative when key experimental conditions are captured. While including temperature does not fully close the performance gap between models trained on low- and high-fidelity solubility data, it significantly narrows it, offering a practical pathway to improve predictions from historical or literature-derived datasets.
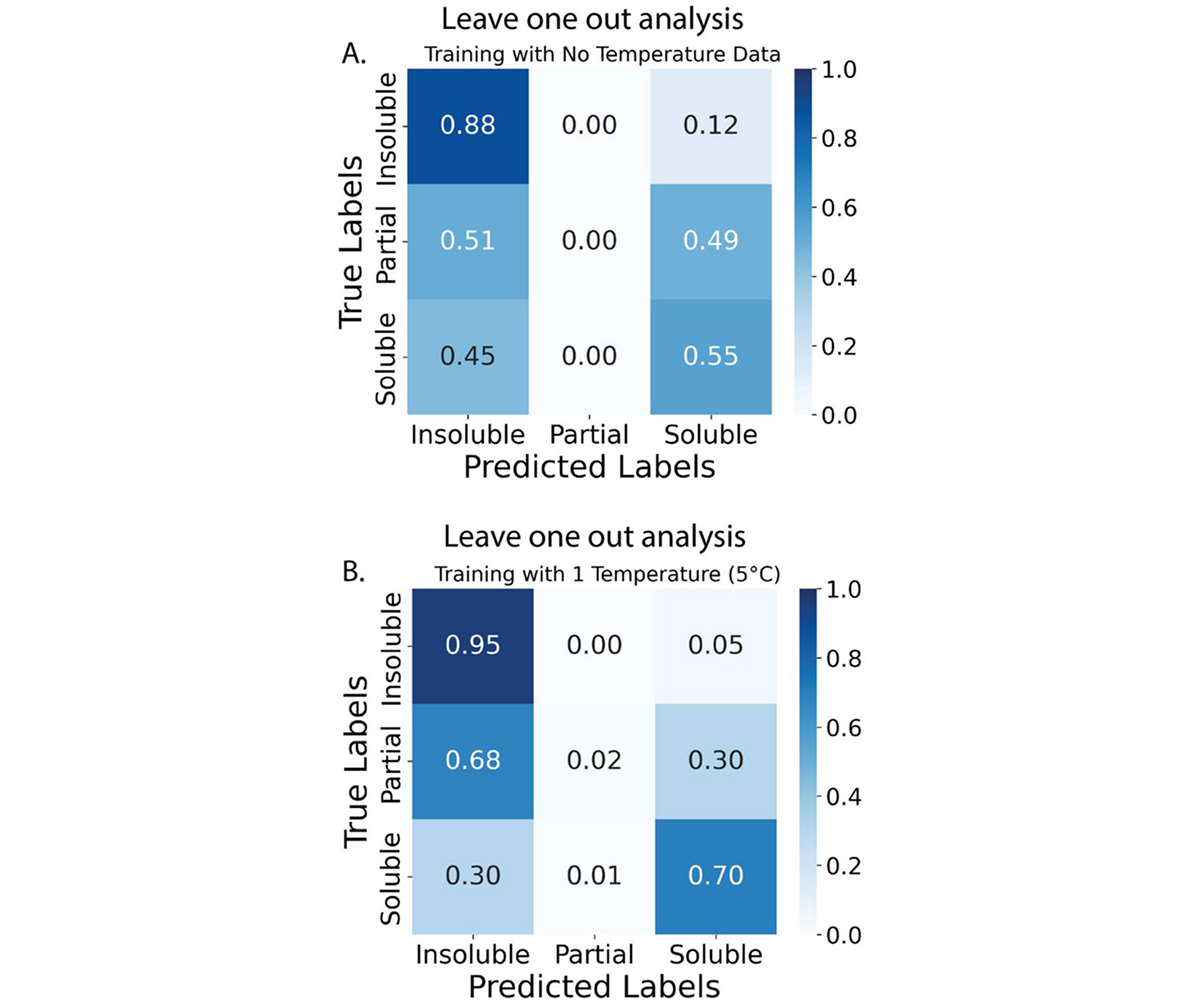
Figure 3: The Leave-one-out (LOO) analysis of the turbidity data based on the temperature groupings. This dataset has been extracted on the equilibrium hold for 10, 25 and 60 degrees Celsius. The model was trained under the conditions: (A) training with no temperature data (using previously unseen polymer-solvent pairs, we hold out temperature from training on the randomized subset of data ); (B) training with data from one temperature (10°C).
Conclusion
The study shows that high-quality, standardized experimental data are essential for reliable machine learning predictions of polymer solubility. Because polymer behavior is highly sensitive to temperature and processing conditions, turbidity measurements collected with Crystal16 provide more consistent and informative solubility classification than visual inspection, especially for partially soluble systems. By enabling controlled temperature profiles and high-throughput data collection, Crystal16 generates machine-learning-ready datasets that improve model performance and support confident, data-driven decisions in polymer formulation and materials development.
References
We thank the authors for their valuable contributions and insights. Read the full article: https://onlinelibrary.wiley.com/doi/10.1002/marc.202500454
Crystal16 for polymer studies
Curious how the instrument can advance your polymer research? Contact us for a demo tailored to your needs!